Ms. Pac-Man Autonomous Agents
DESCRIPTION
Three autonomous agents built to play Ms. Pac-Man, each using a fundamentally different decision-making approach. The Heuristic agent relies on hand-crafted rules and graph-based pathfinding. The MCTS agent plans ahead by simulating future game states before acting. The Deep Q-Network agent learns a control policy through thousands of episodes of trial and error. All three agents were developed on top of a provided Java–Python framework and are evaluated under identical conditions.
SCREENSHOTS
MY ROLE & CONTRIBUTION
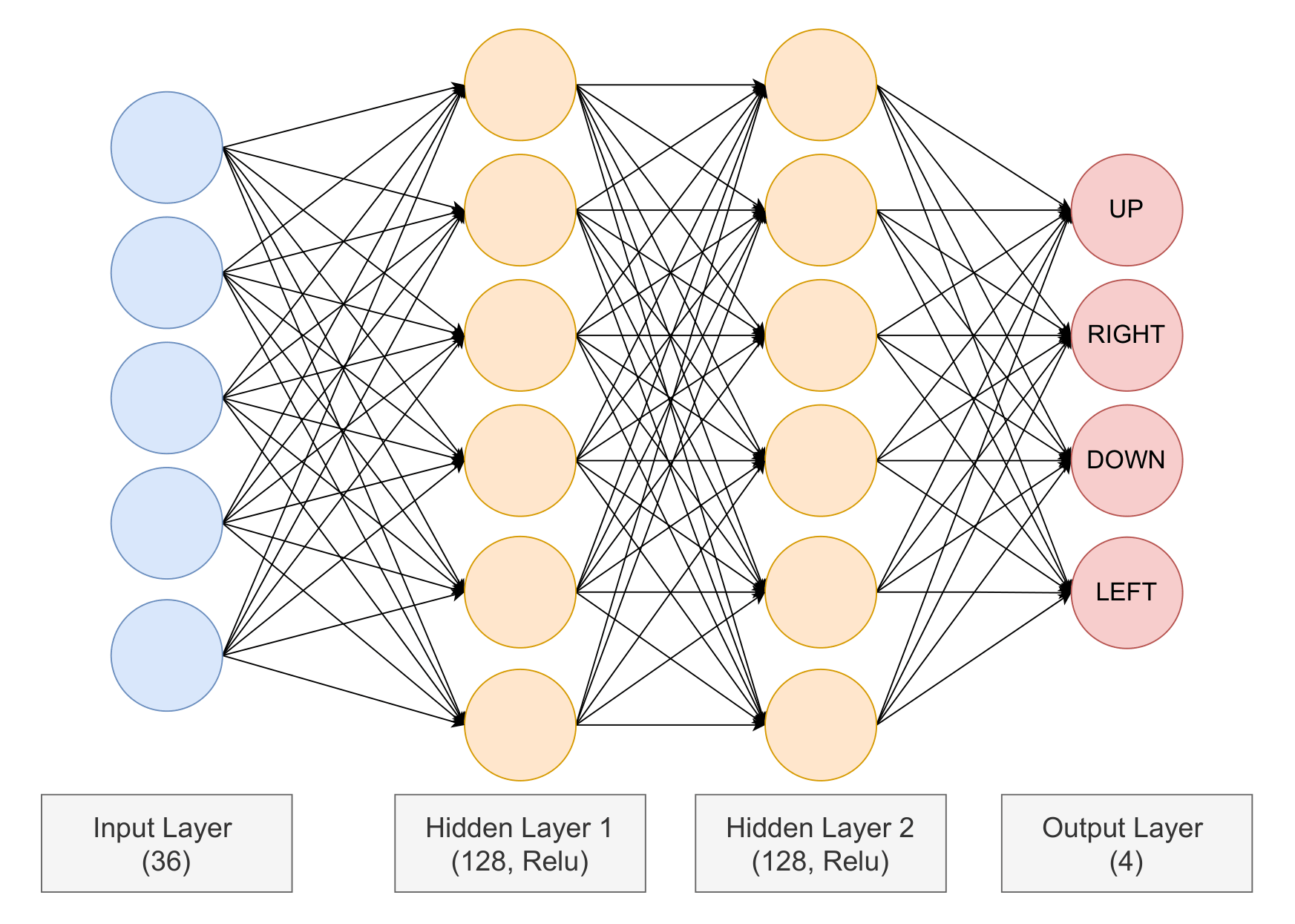
I designed and implemented all three agents on top of the provided Java–Python framework. For the Heuristic agent, I built an incremental BFS graph system and a priority-based mode selection pipeline covering flee, chase, pill collection, and exploration behaviors. For the MCTS agent, I implemented the full four-phase search cycle with UCB1 selection, random rollouts, and an adaptive simulation budget. For the RL agent, I designed a 36-dimensional state representation, implemented a Double DQN with experience replay, reward shaping, and action masking, and iterated from a failed tabular Q-learning attempt to a working deep learning solution using PyTorch.
CORE CONCEPTS
This project explores the trade-offs between rule-based, planning-based, and learning-based approaches to real-time game control. It applies graph search, tree-based forward planning, and deep reinforcement learning to the same environment, making the comparison direct and meaningful. A key insight from the results is that hand-crafted domain knowledge can outperform both planning and learning under limited evaluation conditions, while learned policies show potential for higher peaks at the cost of consistency.
TECHNICAL ASPECTS
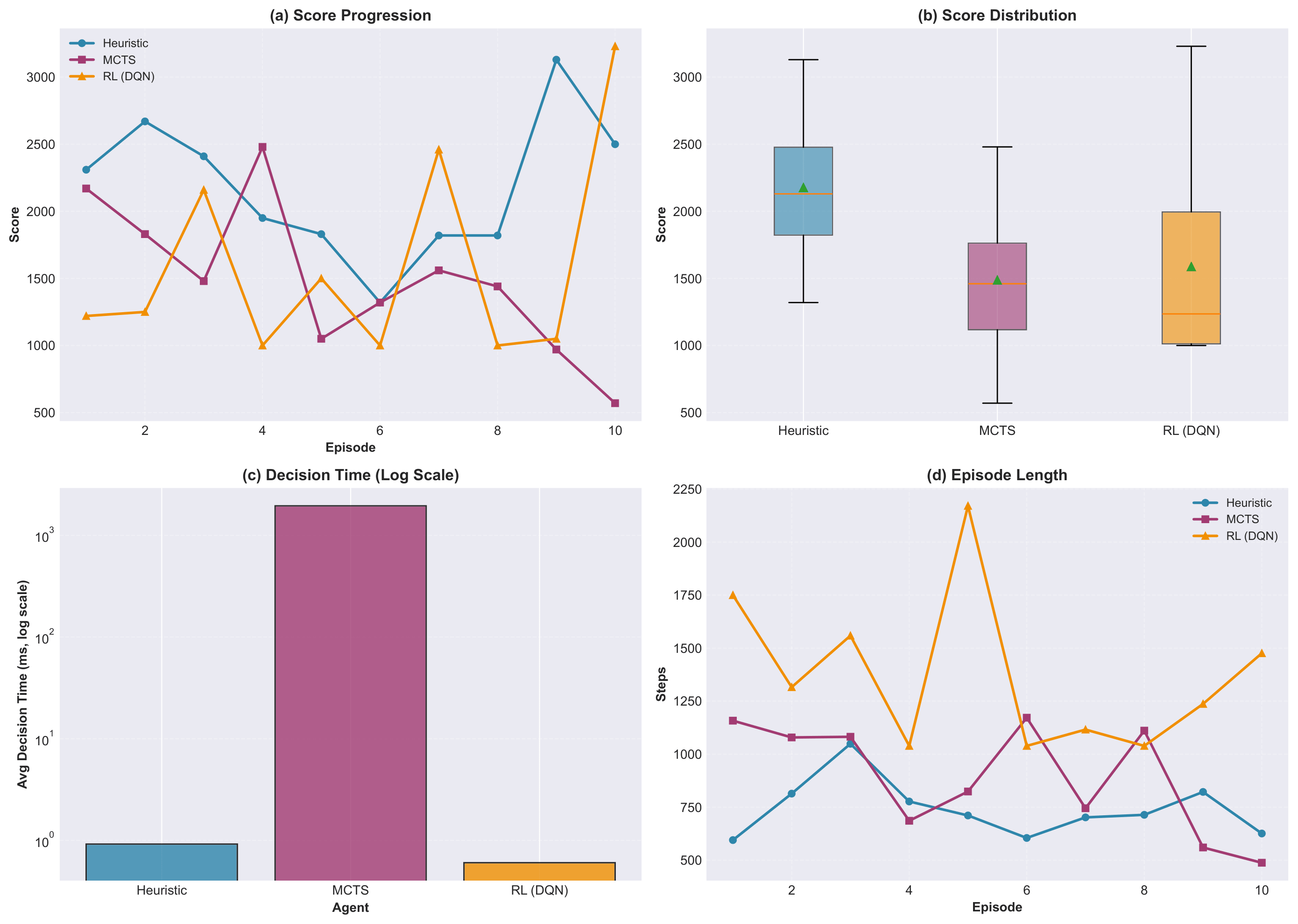
Developed in Python on top of a provided Java game server. The RL agent uses a fully connected network (36→128→128→4) trained with Double DQN, ε-greedy exploration decaying over 500,000 steps, and a replay buffer of 200,000 transitions. Evaluated over 10 episodes per agent. The Heuristic agent averaged 2176 points at under 1ms per decision, MCTS averaged 1487 points at ~1950ms per decision, and the DQN agent averaged 1587 points with a best score of 3230.
COURSE: "Autonomous Agent Systems" – MSc in Artificial Intelligence for Games, Universidade Lusófona (1º year, 1º semester)
PLATFORM: Python / Java
DEVELOPMENT TIME: ~1 Month
TEAM SIZE: 1 developer
TECHNOLOGIES USED: